The ABC of Computational Text Analysis
#8 Ethics and the Evolution of NLP
Alex Flückiger
Faculty of Humanities and Social
Sciences
University of Lucerne
28 April 2022
Recap last Lecture
- assignment 2 accomplished ✅
- an abundance of data sources
- JSTOR, Nexis, few datasets
- creating your own dataset
- convert any data to
.txt
- convert any data to
- processing a batch of files
- perform tasks in for-loop
Outline
- ethics is everywhere 🙈🙉🙊
- … and your responsibility
- understand the development of modern NLP 🚀
- … or how to put words into computers
Ethics is more than philosophy.
It is
everywhere.
An Example
You are applying for a job at a big company.
Does your CV pass the automatic pre-filtering?
🔴 🟢
🤔 For what reasons?
Your interview is recorded. 😎 🥵
What personal traits are inferred
from that?
🤔 Is it a good reflection of your personality?

Don’t worry about the future …
… worry about the present.
- AI is persuasive in everyday’s life
- assessing risks and performances (credits, job, crimes, terrorism etc.)
- AI is extremely capable
- AI is not so smart and often poorly evaluated
💡 What is going on behind the scene?
An (R)evolution of NLP
From Bag of Words to Embeddings
Putting Words into Computers (Smith 2020; Church and Liberman 2021)
- from coarse, static to fine, contextual meaning
- how to measure similarity of words
- string-based
- syntactic (e.g., part-of-speech)
- semantic (e.g., animate)
- embedding as abstract representations
- from counting to learning representations
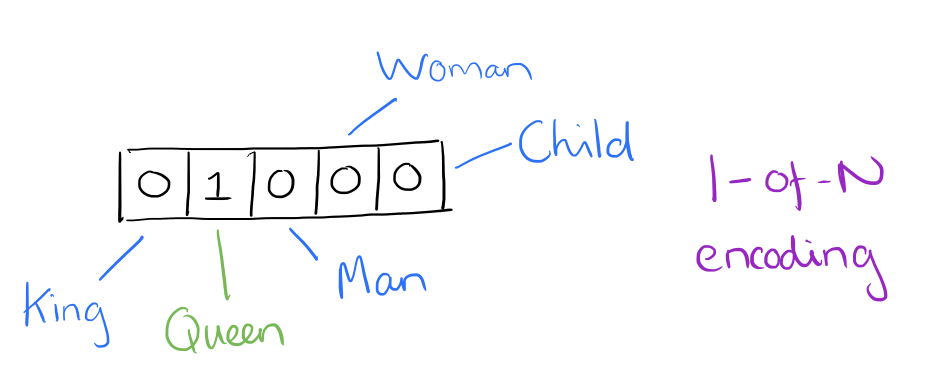
Bag of Words
- word as arbitrary, discrete numbers
King = 1, Queen = 2, Man = 3, Woman = 4
- intrinsic meaning
- how are these words similar?
Representing a Corpus
Collection of Documents
NLP is great. I love NLP.I understand NLP.NLP, NLP, NLP.
Document Term Matrix
NLP |
I |
is |
term | |
|---|---|---|---|---|
| Doc 1 | 2 | 1 | 1 | … |
| Doc 2 | 1 | 1 | 0 | … |
| Doc 3 | 3 | 0 | 0 | … |
| Doc ID | … | … | … | term frequency |
“I eat a hot ___ for
lunch.”
You shall know a word by the company it keeps!
Firth (1957)
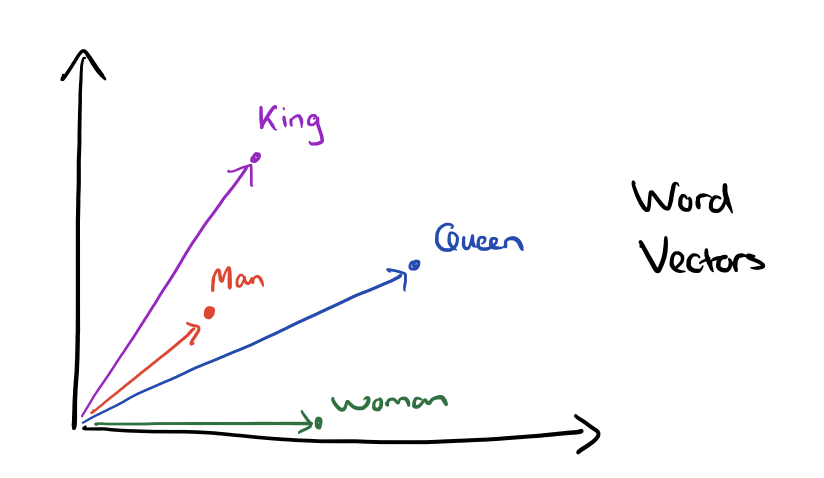
Word Embeddings
word2vec (Mikolov et al. 2013)
- words as continuous vectors
- accounting for similarity between words
- semantic similarity
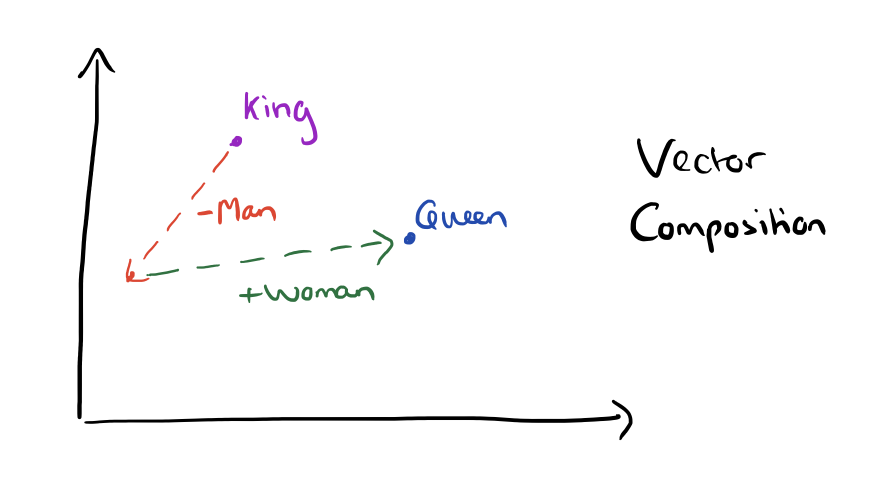
King – Man + Woman = QueenFrance / Paris = Switzerland / Bern
Contextualized Word Embeddings
BERT (Devlin et al. 2019)
- recontextualize static word embedding
- different embeddings in different contexts
- accounting for ambiguity (e.g.,
bank)
- acquire linguistic knowledge from language models (LM)
- LM predict next/missing word
- pre-trained on massive data (> 300 billions words)
💥 embeddings are the cornerstone of modern NLP
Modern NLP is propelled by data
Learning Associations from Data
«___
becomes a doctor.»

Cultural Associations in Training Data
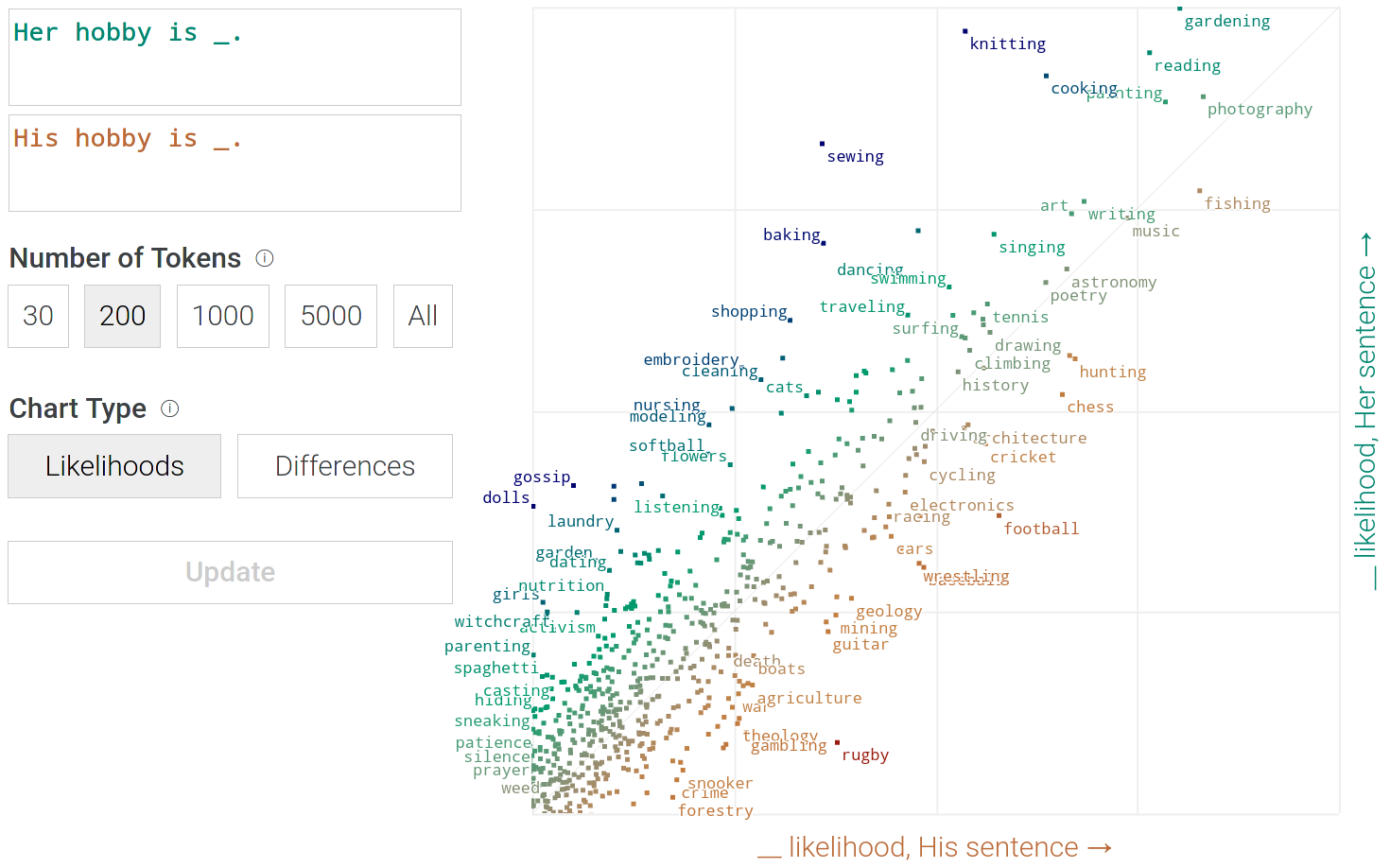
Word Embeddings are biased …
… because
our data is we are biased. (Bender et al.
2021)
In-class: Exercises I
- Open the following website in your browser: https://pair.withgoogle.com/explorables/fill-in-the-blank/
- Read the the article and play around with the interactive demo.
- What works surprisingly well? What is flawed by societal bias? Where do you see limits of large language models?
Modern AI = DL
How does Deep Learning work?
Deep Learning works like a huge bureaucracy
- start with random prediction
- blame units for contributing to wrong predictions
- adjust units based on the accounted blame
- repeat the cycle
🤓 train with gradient descent, a series of small steps taken to minimize an error function
Limitations of data-driven Deep Learning
„This sentence
contains 32 characters.“
„Dieser Satz enthält 32
Buchstaben.“
Current State of Deep Learning
Extremely powerful but … (Bengio, Lecun, and Hinton 2021)
- great at learning patterns, yet reasoning in its infancy
- requires tons of data due to inefficient learning
- generalizes poorly
Biased Data and beyond
Data = Digital Traces = Social Artifacts
- collecting, curating, preserving traces
- data is imperfect, always
- social bias, noise, lack of data etc.
- data is more a tool to refine questions rather than a reflection of the world
Data vs. Capta
Differences in the etymological roots of the terms data and capta make the distinction between constructivist and realist approaches clear. Capta is “taken” actively while data is assumed to be a “given” able to be recorded and observed.
Humanistic inquiry acknowledges the situated, partial, and constitutive character of knowledge production, the recognition that knowledge is constructed, taken, not simply given as a natural representation of pre-existing fact.
Drucker (2011)
Raw data is an oxymoron.
Gitelman (2013)
Two Sides of the AI Coin
Explaining vs. Solving
- conduct research to understand matters in science
- automate matters in business using applied AI
Still doubts about practical implications?
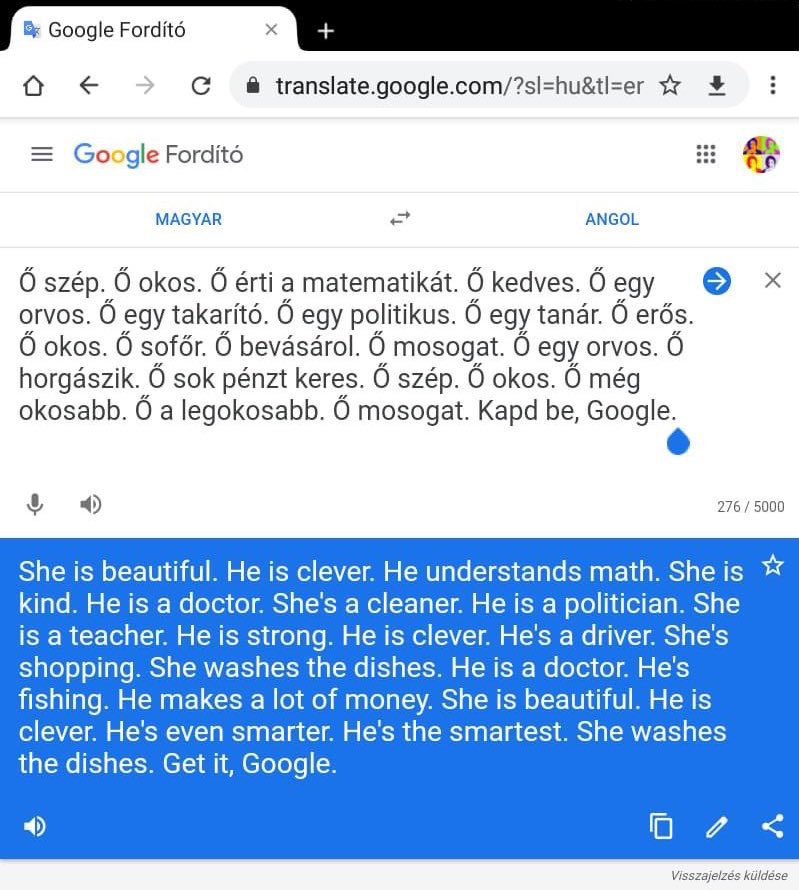
And it goes on …
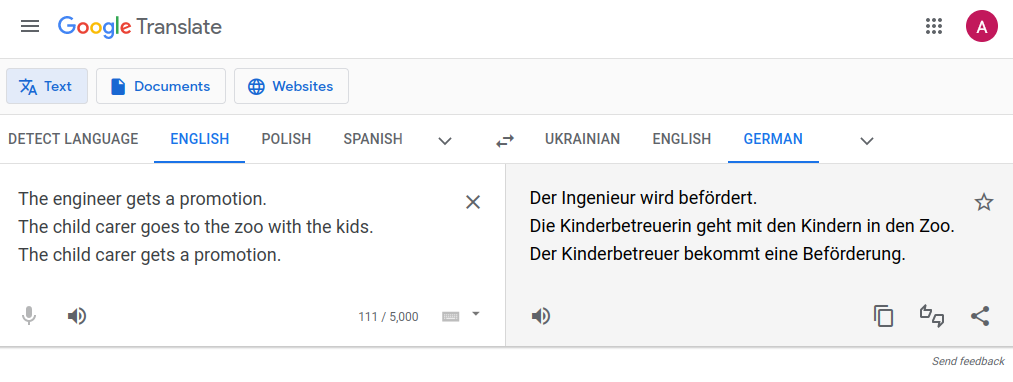
Fair is a Fad
- companies also engage in fair AI to avoid regulation
- Fair and good – but to whom? (Kalluri 2020 )
- lacking democratic legitimacy
Don’t ask if artificial intelligence is good or fair,
ask how it shifts power.Kalluri (2020)
Data represents real life.
Don’t be a fool. Be wise, think twice.